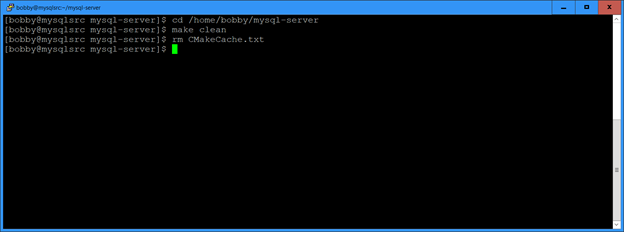
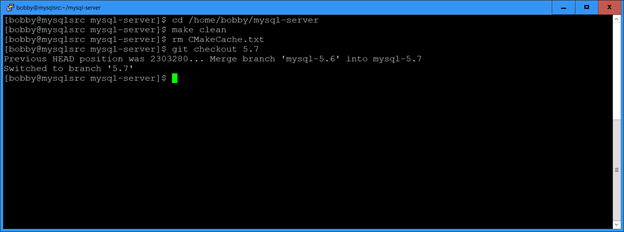
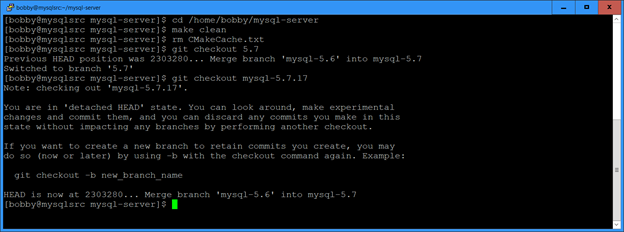
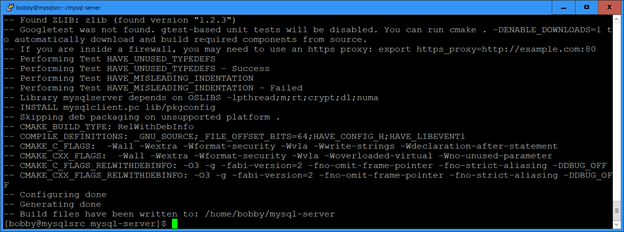
For Oracle versions 11.2 through 18 I have been applying quarterly patches to a test database and then gathering the Oracle home into a tar file. When we want to roll out a new database server with the latest patches, we untar the file and clone the Oracle home with a command like this:
$ORACLE_HOME/oui/bin/runInstaller -clone -silent ...
This command no longer works for 19c. Here are the errors I got out of runInstaller:
Notice that the version of runInstaller is 12.2.0.7.0 even though I am installing from a 19c download.
Now I am using a new command like this while in the $ORACLE_HOME directory:
./runInstaller -silent -responseFile ./myresponsefile.rsp
Before running this command, I had to unzip my gold image zip file into $ORACLE_HOME. I created the gold image zip file using a command like this:
I ran this through MobaXterm to use their X server. I created the response file when I initially installed 19c on this test server. Then I patched the Oracle home with the July 2019 PSU and finally ran the above command to create the gold image.
Some useful links that I ran into:
Franck Pachot’s post about doing a silent 18c install using the new runInstaller
Oracle support document that says the old Oracle home cloning does not work in 19c:
19.x:Clone.pl script is deprecated and how to clone using gold-image (Doc ID 2565006.1)
Oracle documentation about installing silent with response file
I tried running the $ORACLE_HOME runInstaller without a response file based on the Oracle support document 2565006.1 listed above but it gave an error saying that I needed a global database name even though I am doing a software only install. Here is what I tried:
./runInstaller -silent -debug -force \ oracle.install.option=INSTALL_DB_SWONLY \ UNIX_GROUP_NAME=oracle \ ORACLE_HOME=$ORACLE_HOME \ ORACLE_BASE=$ORACLE_BASE \ oracle.install.db.InstallEdition=EE \ oracle.install.db.DBA_GROUP=dba \ oracle.install.db.OPER_GROUP=oracle \ oracle.install.db.OSBACKUPDBA_GROUP=oracle \ oracle.install.db.OSDGDBA_GROUP=oracle \ oracle.install.db.OSKMDBA_GROUP=oracle \ oracle.install.db.OSRACDBA_GROUP=oracle \ DECLINE_SECURITY_UPDATES=true
So I switched to a response file based on this DBA Stackexchange post about how you have to use a response file because the command line options don’t work. I am not sure why the Oracle document shows the command line options if they don’t work.
We used the Oracle home cloning approach for several years with a lot of success. 19c has a new way to do the same thing and it was not difficult to modify our existing scripts and process to use the new method. Going forward I will apply quarterly 19c patch sets to my test database and then create a new gold image zip file for future deployments. I plan to continue to use the older Oracle home cloning method for 12.2 and 18c for now if it keeps working. For 12.2 and 18c I just apply quarterly updates to our test database servers and create new Oracle home tars for deployments.
Bobby