1. Introduction
I just finished moving and upgrading an Oracle database from 11.2.0.4 on HP Unix Itanium to 19c on x86-64 Linux on VMWare along with an army of coworkers on our project team. I want to use this post to describe the choices I considered for migrating the data from the old to the new system. I mention my coworkers because this was a major collaborative effort and I do not want to take credit for the work of others. But I did have to think through the best way to move this big database cross platform and I think that my evaluation of those options in dialog with the project team was a way that I contributed. So, I can blog about it. Also, I think it is worth posting about this subject because the choice of data migration method was challenging and interesting to me. So, if I can find a way to communicate about it clearly enough it might have value to others and even to myself if I come back to this later.
First, I think I should explain some of the parameters for this upgrade/migration. The database files total about 15 terabytes of space. I guess actual data is 7-8 TB but everything else together adds up to 15. The database has tens of thousands of partitions and subpartitions. These partitions/subpartitions are manipulated by batch processes on the weekend and in the weekday evenings. Some of the tables are partitioned by date but others by columns that are not date related. The source system is running 11.2.0.4 and the target system 19c. The source and target platforms have different endianness. At the beginning of the project our goal was to minimize downtime for the final cutover weekend, so I tried to find methods of cutting over from the old to new database with only an hour or two of downtime max. The system has an online web front end that business users use during the weekdays as well as very resource intensive batch jobs on the weekend and on some weeknights. One goal of the project besides upgrading to a newer platform was to improve performance. On some weekends the batch processes did not complete in time for the users to see the updated data on Monday morning. The much faster x86-64 processors on the new system should speed up the weekend batch processes to meet the business need to complete before the Monday workday. CPU was pegged for several hours each weekend on the older HP Itanium system so we knew that newer, faster CPUs would help.
2. Transportable Tablespaces and Cross Platform Incremental Backup
Next, I want to talk about different options we considered. Another DBA on my team worked with an earlier proof of concept for this project to show the potential benefits of it. At some point she tried out the ideas in an earlier version of this Oracle support document:
This is a fairly complicated procedure designed to speed up the move from Unix to Linux by allowing you to use Transportable Tablespaces to move your data over, converting to the new endianness, and then apply incremental backups of the source system to catch up any changes, changing endianness of the backups as you go. Transportable Tablespaces are kind of a pain, but I have worked on them before and they can be done. But the key limitation of this process is that just before you go live on the new system you must use Data Pump to import all the metadata from your source database. But since we have tens of thousands of partitions and subpartitions the time to import the metadata could be several hours. So, I felt like we could use this approach but with all the complexity and risk we still might have a lengthy period of downtime and another approach might work better. I think the key lesson from this approach is how hard it is to change endianness using a physical backup when you have a huge data dictionary. If we were moving from Linux to Linux, we probably could have used some sort of physical copy along with the application of incremental changes without the big metadata import at the end. But with the big data dictionary and the cross-platform nature of the upgrade the physical copy option (transportable tablespaces) seemed too slow.
One reason I liked this option was that it would work well with NOLOGGING changes. I was concerned early on that I could not use replication methods that pulled changes from the redo logs because some updates would not be logged. But incremental backups do pick up blocks that are updated even if the updates are not written to the redo logs. Eventually I did a bunch of research and found that I could turn on FORCE LOGGING on the source database and that opened up the option of using the redo logs. The problem of the long time to export/import the metadata with the Transportable Tablespaces option pushed me to pursue the FORCE LOGGING research to make sure we could use it.
3. Pre-Loading Static Historical Data
The second approach I considered and discussed with the team early on was exporting and importing historical data in advance and only migrating over actively updated data during the cutover window. If you have most of your data in tables that are partitioned by a date column you could potentially pre-load the older static data on your new system and then migrate a small percentage of your 15 terabyte database during the cutover window. I found that about 4 terabytes had not been updated in the past 90 days and that made me stop pursuing this option. Here is the script I used: statictabsum.sql. I just looked at the last_analyzed date on tables, indexes, partitions, and subpartitions. Not perfect but it gave me some idea of how much data was static. Slightly edited output:
>select sum(bytes)/(1024*1024*1024*1024) total_tb
2 from withlastanalyzed
3 where
4 last_analyzed < sysdate - &&DAYSOLD;
TOTAL_TB
----------
4.34381223The system that I was upgrading is a pretty complicated system with many batch jobs and many interfaces with external systems. I would have to work with the development team to understand what data was truly static and there would be the chance that we would make a mistake and not copy something that we should. I would hate to go live and find that I missed some data that should have been updated on the partitions that I thought were static. Yikes! With my imperfect estimate of how much data could be pre-loaded and knowing the complexity of the system I felt that it was not worth trying the pre-load of the static data.
4. Oracle GoldenGate Replication
The third thing I tried, and thought would work really well for us, was Oracle GoldenGate replication. Several years ago, a coworker of mine had upgraded and migrated the database for a transactional system using GoldenGate with minimal downtime. Oracle has a white paper about how to do this:
Zero Downtime Database Upgrade Using Oracle GoldenGate
The idea is to start capturing changes to your source system and then do a full export/import to your target system. Then apply all the changes that happened on the source database during the export/import to the target db using GoldenGate. We had this setup and began testing it but we had failures because of changes to table partitions and subpartitions by the application batch jobs. We had setup GoldenGate to replicate DML but not DDL. We researched it in the manuals and found that to replicate DDL (partition drops and adds) the source system had to be 11.2.0.4 or later and have compatibility set to 11.2.0.4 or later to do DDL replication in the most current and desirable way. See this section of the 12.2.0.1 installation manual:
13.1.1 Support for DDL capture in integrated capture mode
Unfortunately, even though our source system was on 11.2.0.4 the compatible parameter was set to 11.2.0, the default. I wonder why 11.2.0.4 defaults to compatible=11.2.0? Sure, we could change the parameter, but you cannot easily back out a change to compatible. And we would essentially have to retest our entire application before changing it. Given that our project was running out of time and money that was not an option. So, that led to our final choice.
5. Data Pump Export and Import
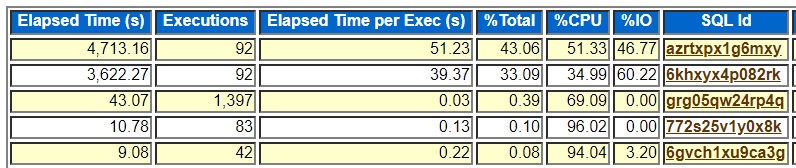
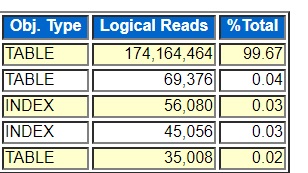
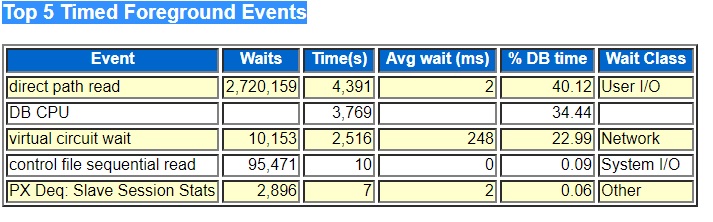
The last migration method that we considered and the one we just used in the production migration was Oracle Data Pump export and import, the expdp and impdp utilities. This is the simplest and most widely used method for copying data from one Oracle database to another and it works great across platforms with different endianness and different versions of Oracle. We used this method to populate our new databases for testing. Originally we thought about using the same data migration method for testing that we planned to do for the final production cutover but we did not have the time and money to get GoldenGate setup before all the testing began so we were not able to use it to populate our test databases. We had to use the simpler Data Pump utility. We had a whole crew of people lined up to work on the project, so we had to simply do a full export/import and cut them loose. As the project went on we streamlined our export/import method including working with Oracle support to get a fix for a bug that affected our data migrations. As our project had dragged on for a number of months beyond our initial deadline and as we discovered that GoldenGate was not going to work for us without a lot of more work I started to think about using Data Pump export/import, our last resort. At the time it was taking 50 hours to do the full export/import and I asked if we could get approval for two extra days of downtime – two full working days of application downtime. To me 50 hours to migrate a 15-terabyte database was not bad. I had expected it to take several days based on prior experiences populating dev and test databases from this same source system. The HP Unix hardware was older and had slower network adapters so that was part of the reason for the long data migration time.
Once we got the approval to take the extra downtime, I had to fend off suggestions to go back to preloading the historical data or to ignore tables that we think are obsolete. By this time, I was convinced that a full export/import made the most sense because all our testing was done on systems that were populated with the same method. We had the business approval for the downtime, and we knew that we had been testing for months on databases that had been populated with this method. Finally, our Unix/Linux/Storage team came up with a clever way to cut our export/import time almost in half without changing anything on the database side. Essentially, they figured out how to move the filesystem that we were exporting to onto an HP Unix blade with a faster network adapter. The original system had a 1 gigabit network adapter and the new system had 10 gigabit. Also, they setup an NFS mounted filesystem so we could import straight over the network rather than copy all the files to the target server and have all that duplicate storage space. We tested this approach several times and then the real thing went in without issues and even a little faster than we expected.
6. Conclusion
My main concern for this project was how to migrate such a large database and change the endianness of the data in a short enough time to meet the needs of our users and our company. This concern drove me to investigate several potentially complicated approaches to this data migration. But in the end, we used the simplest and surest method that we had already used to populate our test databases. We took several steps to tune our full Data Pump export/import process. The seven largest tables were broken out into their own parfile and exported to disk uncompressed in parallel. Their indexes were rebuilt parallel nologging. Then the Unix/Linux/Storage team did their magic with the faster network adapter. But even with these helpful performance enhancements our approach was still simple – Data Pump export and import. The more exotic methods that we tried were thwarted by the nature of the database we were upgrading. It had too many subpartitions. The application manipulated the subpartitions during the week. We had the wrong compatible value. Finally, budget and schedule concerns forced the decision to go with what worked, export/import. And in the end, it worked well.
I want to conclude this post with high level lessons that I learned from this process. There is value in simplicity. Do not use a more complex solution when a simpler one meets your needs. The Transportable Tablespaces and GoldenGate options both were cool to work on and think about. But it takes time to dig into things and complexity adds risk of failure. If a simpler solution is safer, meets the business need, and takes less time and money why not use it? I guess the other high-level lesson is that it is easier to get approval for downtime when your project is behind schedule and over budget. When push came to shove downtime was less important than when we went live. Maybe if I had pushed for the longer downtime from the beginning and planned all along to use export/import the project would have been shorter. But I did not know that GoldenGate would run into the issues it did, so it was harder to insist that there was no way to eliminate substantial downtime up front. I also did not know at the beginning of the project that the export/import method could be streamlined to run in 1 day instead of several. Maybe the real lesson is that you have to work through these data migration options along with your project team and make the best choices that you can at the time based on technical issues that you discover and the business needs as they evolve with the project. This project ended with a simple data migration approach that met the company’s needs, but future projects may have different technical and business parameters and the other more complex approaches may be more appropriate to future situations.
Bobby