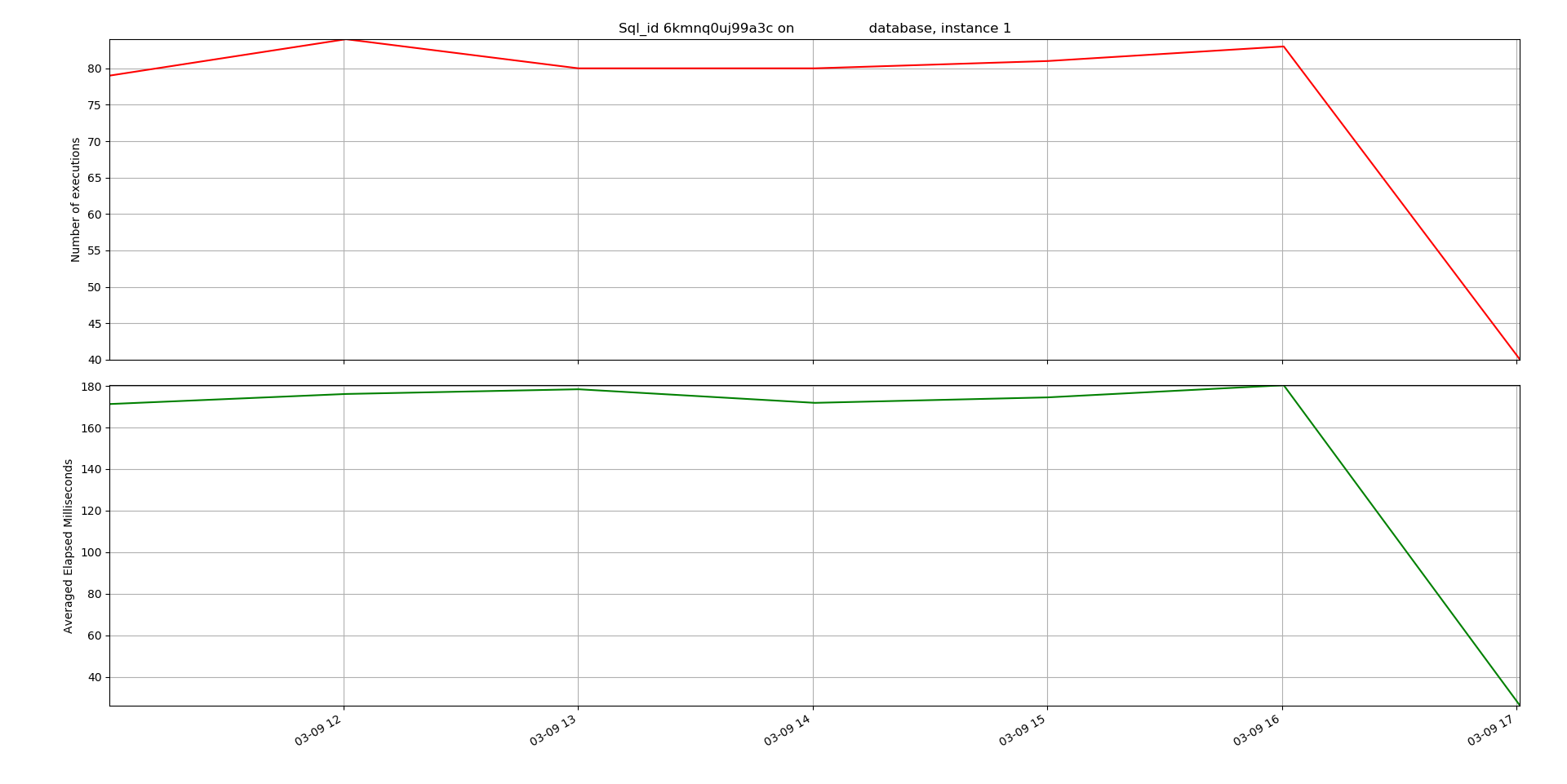
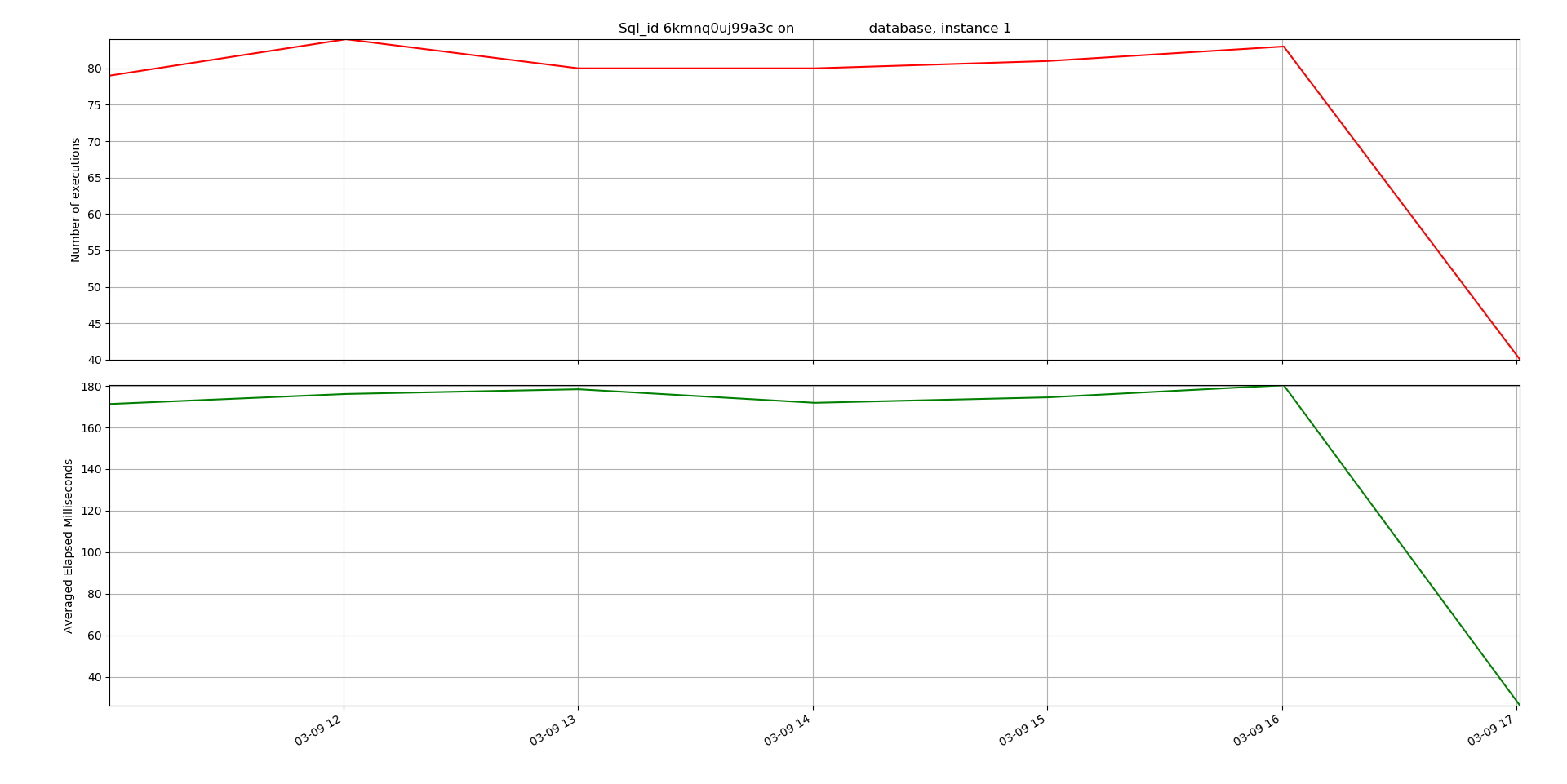
It has been two years or more since I first thought about moving my blog to Amazon Web Services (AWS) from iPage, the hosting company that this blog has always been on. My company uses AWS for a number of cloud initiatives, and I need to learn more about it. I thought it made sense to make moving my blog a little cloud training project for me. Plus, there were a couple of things that I wanted to improve over my experience with iPage. My point is not to criticize them. It has been great having a blog, and iPage made it easy to get started. But performance of my blog has really gone down. Often my site was so slow that updates would time out and often the blog would just hang. Also, I wanted to get full control over the environment and have a Linux host that I could ssh into. So, it made sense to move to AWS and put my blog on an EC2 Linux virtual machine. But I put it off until now because it seemed like too big of a project. It turned out to not be that bad. I felt like I had a little extra time at the beginning of the year before we get deep into new projects for 2021 so it made sense to do this simple cloud project. I am glad that I did it because now my blog is more responsive, and I learned a lot about AWS and hosting a web site.
My move to AWS revolved around me reading a number of informative web pages – mostly AWS tutorial pages – so I want to put the links to them in this post and describe things I learned from them or ways that I deviated from them. First off, I created an AWS account for myself two years ago and let it sit. I do not recommend this approach. I probably could have saved myself a little money on free tier pricing if I created the account right before I started on the blog migration. But I do not care. The money is not very much, and the training is worth far more. I do not have the link to whatever page I used to setup my AWS account but it was not hard. You need a credit card pretty much. I ended up deciding to use the same Oregon region that my company uses since it is out West near where I live in Arizona.
Since I already had an AWS account my first step was to see how to setup an EC2 instance that would hold a WordPress blog. Since I want to save money I chose the inexpensive t2.micro size instance which has 1 core and 1 gigabyte of memory with 8 gigabytes of storage. Hopefully I could run this simple blog on an affordable instance. I knew from iPage support that I was running in around 128-256 megabytes of memory on their shared server so hopefully a 1 GB memory host would be enough. The first tutorial I used showed me how to setup a “LAMP” server which would support WordPress on an EC2:
Tutorial: Install a LAMP web server on Amazon Linux 2
It seems that “Amazon Linux 2” is the latest version so I went with that. The biggest change I ended up making from this tutorial is that I wanted to use PHP 7.4 which WordPress recommends. So, I changed this line from the tutorial:
sudo amazon-linux-extras install -y lamp-mariadb10.2-php7.2 php7.2
to
sudo amazon-linux-extras install php7.4
Much later on when I was trying to get Jetpack to work I ended up installing php-xml as well with:
sudo yum install php-xml
I thought about trying to install the latest version of MySQL but got bogged down trying to figure out the right yum command so I just stuck with the MariaDB install as listed in the tutorial. The only other thing from this tutorial is that after migrating my blog’s files over I had to rerun the chmod commands listed to get the directories and files to have the group permissions needed to run updates. So, I ran it once to get the server setup but much later I ran it again with all my files in place.
Now that I had the LAMP server setup on my small EC2 instance I needed to install WordPress just to get a basic install working. Later I would overwrite all the WordPress files with ones from my iPage host. I followed this tutorial:
Tutorial: Host a WordPress blog on Amazon Linux 2
One problem with the tutorial is that it left it where I could not do WordPress updates without an FTP password. But with my EC2 I could only use a key file to login so I followed the instructions in this URL to fix it where I could run updates without a password:
https://stackoverflow.com/questions/640409/can-i-install-update-wordpress-plugins-without-providing-ftp-access
I did:
chmod -R 775 ./wp-content
vi wp-config.php
# add the next line:
define('FS_METHOD', 'direct');
The only other thing I could say about this tutorial is that it does not include things like how to deal with plugins like Wordfence and Jetpack that I had to deal with later in the migration.
After getting a basic WordPress instance working on an EC2, I had to figure out how the internet works. I really have not messed that much with domain registration and DNS records prior to this. In the end it was much simpler than it seemed at first. After looking at tutorials on moving domains to AWS I figured out what seemed like a safe path. Leave the domain registration with iPage and keep using the iPage name servers but point the web server DNS records to my EC2 instance. If something went wrong, I could just point the DNS records back to iPage, delete everything from AWS, and I would be no worse off than when I started. I ended up doing the following steps to get my blog working and up on AWS but still with the domain and DNS at iPage:
- Put an under-construction message on my current blog
- Backup current down EC2 to snapshot
- Setup Elastic IP and bring up EC2
- Copy database from iPage to EC2 with edits
- Copy files from iPage to EC2 with edits
- Move DNS entries from iPage host (for web only) to EC2 and test
- Setup certificate with Certbot
I edited this list for clarity because I did some wrong things that failed but these are the steps that really worked. I had to setup the certificate after switching over the DNS to point to the EC2. One key thing I learned was that you really needed to get a domain pointed to your site before you could finish setting it up. That is a bit of a pain when you are moving from one site to another.
I put a post out there letting people know this blog would be up and down. Then I posted an update about how things are going and kept updating it with PS’s.
Backing up an EC2 is a lot like taking a snapshot of a virtual machine in VirtualBox. You just stop the EC2 instance and take a snapshot of its volume. My small instance only has one volume which is the root filesystem /. The only thing I had to figure out was that the device name for the root filesystem was /dev/xvda. You must know that when you restore a volume from a snapshot. Works well. Nice to be able to take snapshots and restore from them.
An Elastic IP is Amazon’s term for an IP address that is on the internet. If you create an Elastic IP address and associate it with an EC2 instance, then it will always have that address after you stop and start it. Otherwise your instance’s public IP address changes with every stop and start. For me I was using Putty and WinSCP to access the host and it was nice to finally get a consistent IP address. Also, I could setup my DNS entries to point to an IP address that would not change which is good since I am stopping and starting the EC2 instance all the time. Documentation for Elastic IP:
Elastic IP addresses
Copying the database was not hard. I had played with this years ago. You download the SQL script to rebuild and load the MySQL tables for the blog database through phpMyAdmin in iPage’s GUI control panel. Was only about a 27-megabyte file. I just had to edit it to have my database name. IPage had a bunch of letters and numbers as the database name and I made up one that was more friendly. I just used WinSCP to copy the edited SQL dump up to my EC2 and ran it against the MariaDB database I had already created when I installed WordPress. The only minor trick was that I did a custom export of the database from iPage telling it to include drop table commands. That way the script dropped the tables created by the initial WordPress install and created new ones.
I ended up copying the files using SCP commands from the EC2 host. They looked like this:
scp -pr -P 2222 bobbydurrettdbacom@ftp.bobbydurrettdba.com:/* .
scp -p -P 2222 bobbydurrettdbacom@ftp.bobbydurrettdba.com:/.* .
I was worried that I might miss an error copying a file and not notice it, but I just ran these commands manually and they seemed to run fine so I did not worry about it.
The most interesting thing was how simple it was to move the DNS records from my iPage host to the new one. There were two “A” records for the web site. One was for bobbydurrettdba.com and the other for www.bobbydurrettdba.com. I just made a note of the current IP address of my host on iPage and replaced it with the Elastic IP address from AWS.
Originally, I tried to use the certificate that I had already paid for through next year. IPage lets you download the certificate and its private key from its GUI control panel. This worked in terms of letting the site be visible, but Jetpack kept throwing these errors:
cURL error 60: SSL certificate problem: unable to get local issuer certificate
I tried everything I could find on the internet and finally concluded that there must be some file that iPage uses with the “chain” of certificates or certificate authorities. Something like that. I didn’t delve that deep into it. I just figured that there was a file that I didn’t have. So, I gave up on the certificate I paid for and installed the free Certbot instead. Here are the instructions I used to setup SSL:
Tutorial: Configure SSL/TLS on Amazon Linux 2
I did not do step 3 to harden it, but I did do the steps at the end called “Certificate automation: Let’s Encrypt with Certbot on Amazon Linux 2”. Those steps gave my site an A rating on https://www.ssllabs.com/ssltest/ so they must do the hardening steps automatically. I tried to do step 2 with my certificate from iPage but that did not work with Jetpack. I think I was missing the file for SSLCACertificateFile in /etc/httpd/conf.d/ssl.conf and that was why I got the certificate error. In any case the Let’s Encrypt with Certbot steps seemed to cure a lot of ills.
I ran into a funny problem at one point in this setup. I ran out of memory. I don’t think I kept the error message. WordPress just told me something was wrong, and I had to update this line in /var/www/html/wp-config.php to see the error:
define('WP_DEBUG', true);
This showed the out of memory error on the PHP web pages. I think you can also send these errors to a log on the filesystem which is probably what I will configure it to do later. But this WP_DEBUG true setting showed me that various PHP scripts were out of memory. The t2.micro instance has 1 gigabyte of memory and no swap. So, when you run out of memory you are out. You cannot swap processes out to disk. I found a bunch of processes named php-fpm using the memory. I had to edit the file /etc/php-fpm.conf to limit my system to 5 php-fhm processes with this setting:
; The maximum number of processes FPM will fork. This has been designed to control
; the global number of processes when using dynamic PM within a lot of pools.
; Use it with caution.
; Note: A value of 0 indicates no limit
; Default Value: 0
;process.max = 128
process.max = 5
So far, the limit of 5 processes has not hurt the site. It is much more responsive than it was before. I may have to increase this later if it gets to be a problem. Right now, I am running with plenty of free memory.
The last steps were to move my DNS entries from iPage and then the domain registration. This tutorial describes moving the DNS entries:
Making Route 53 the DNS service for a domain that’s in use
This was a lot easier than I thought it would be. I only had 5 DNS entries to move. Two were the A records for the web site and 3 were for the email forwarding company ImprovMX. I thought email forwarding would be done within AWS, but it was a lot easier to use the free ImprovMX service. I only get a handful of emails a month. Anyway, you have to setup two MX records and one TXT record for the email forwarding. So, I manually added 5 entries on Route 53 in AWS and moved my DNS from iPage to Amazon. This site shows you which name servers your domain is using and who it is registered by:
https://lookup.icann.org/lookup
Here are the steps to transfer the domain registration:
Transferring registration for a domain to Amazon Route 53
Pretty cool. The domain registration transfer finally finished after 7 days. I shut down my iPage account and I am fully on AWS. I was on iPage for over 8 years and it has been a great value to me, but it was worth it to move my blog to AWS at this time both for the better performance and for the experience messing with AWS.
Bobby
P.S. While waiting for the domain registration transfer to finish I realized that I was not getting any email from my blog site. Evidently AWS blocks email sent from an EC2 instance by default. You have to ask AWS to remove their email block as documented here: How do I remove the restriction on port 25 from my Amazon EC2 instance? They approved it easily, so it was no big deal, but I am still having issues.
I added a couple of yum packages:
yum install sendmail
yum install mailx
Not sure if these were needed. Now I am trying to get “reverse DNS” setup which I think means that when I run nslookup on my IP address it returns bobbydurrettdba.com instead of the Amazon public DNS name. ImprovMX may require this to prevent outgoing email being blocked as spam. This is now working:
>nslookup bobbydurrettdba.com
...
Non-authoritative answer:
Name: bobbydurrettdba.com
Address: 44.241.233.131
>nslookup 44.241.233.131
...
Name: bobbydurrettdba.com
Address: 44.241.233.131
Was not as hard as I thought. This was a helpful page:
https://aws.amazon.com/premiumsupport/knowledge-center/route-53-reverse-dns/
Meanwhile I setup a weekly backup script and a space monitoring script. I also wrote a Python script to automate bringing down the EC2 instance and creating a snapshot of its root volume. There is more that I could say but this is enough for one post.