We have event 27401 level 16384 set on some of our systems and it appears that this is preventing the scheduler from changing the active resource manager plan when the window opens.
I haven’t been able to find any documentation on this event and level. This blog post is all I could find on event 27401 but it doesn’t mention level 16384. So, I did a test on a small test instance on my laptop and was able to show that one effect of activating this event and trace level is to prevent a scheduler window from changing the active resource manager plan. I setup a test case where one session would create a table and get a row lock on that table. Then I would open a new session and run a script that would attempt to update the locked row. My theory is that the second session would appear as an active session. Then I could set the plan to limit active sessions for a given resource manager consumer group to 1 and then any sessions would hang on a resource manager wait event. I must have misunderstood what limiting active sessions to 1 would do because the session that should be hung on a lock wait ended up hung on a resource manager wait but that was fine. My test of the scheduler window was just done by going into the Oracle Enterprise Manager database control on the Server tab and clicking on the Windows link in the Oracle Scheduler section and opening the window for the current day. This should change the active resource manager plan from the one I hacked to limit active sessions to 1 to one that doesn’t limit active sessions. I tried this without setting the event and trace level and the plan changed and the resource manager wait disappeared. I set the event and bounced the instance and then opening the scheduler window didn’t change anything. The plan stayed the same and the session was still hung on the resource manager wait. I don’t recommend setting this event without Oracle support’s recommendation, but if you have it set maybe this post can give you a clue what it might be doing. Here are some screenshots:
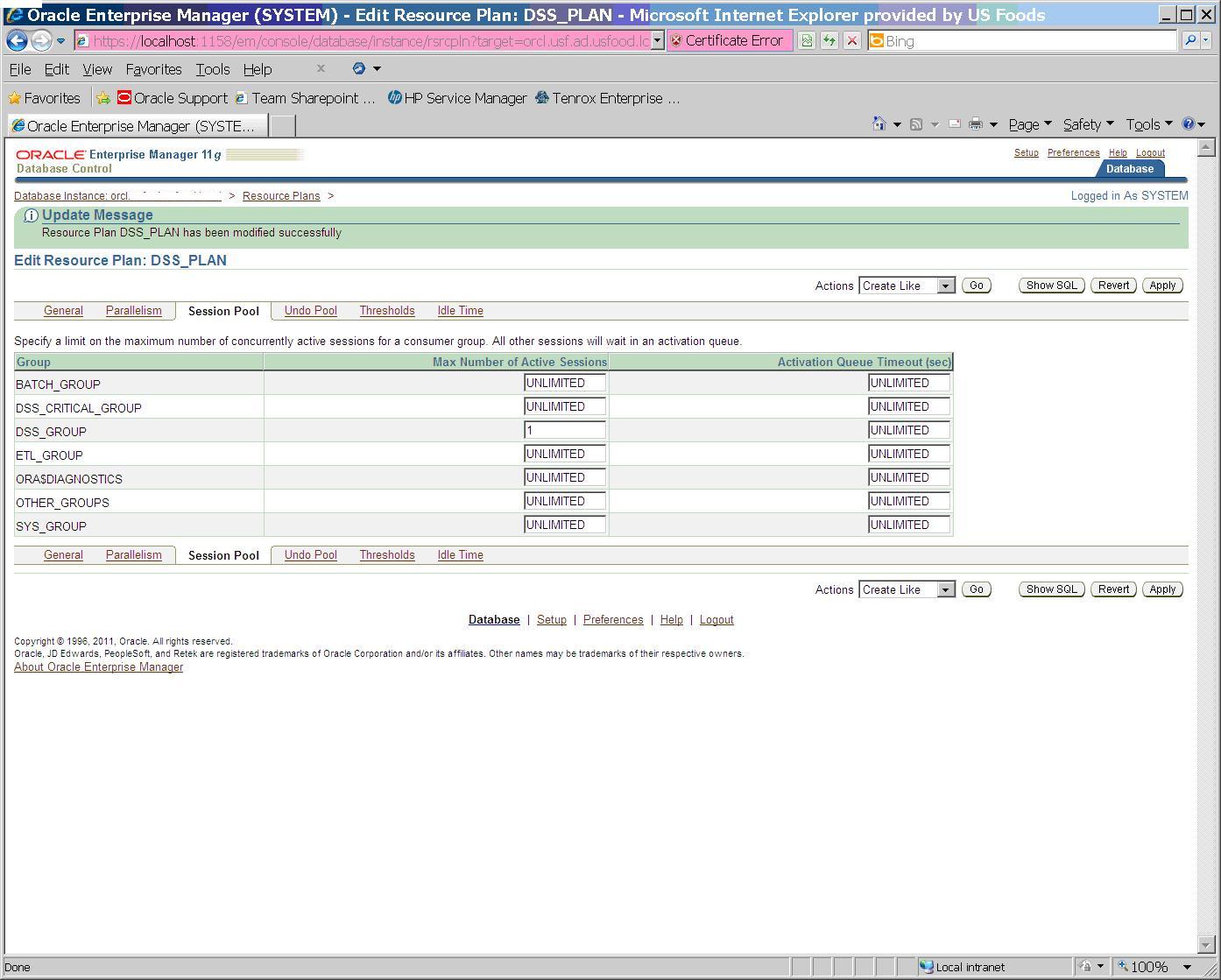
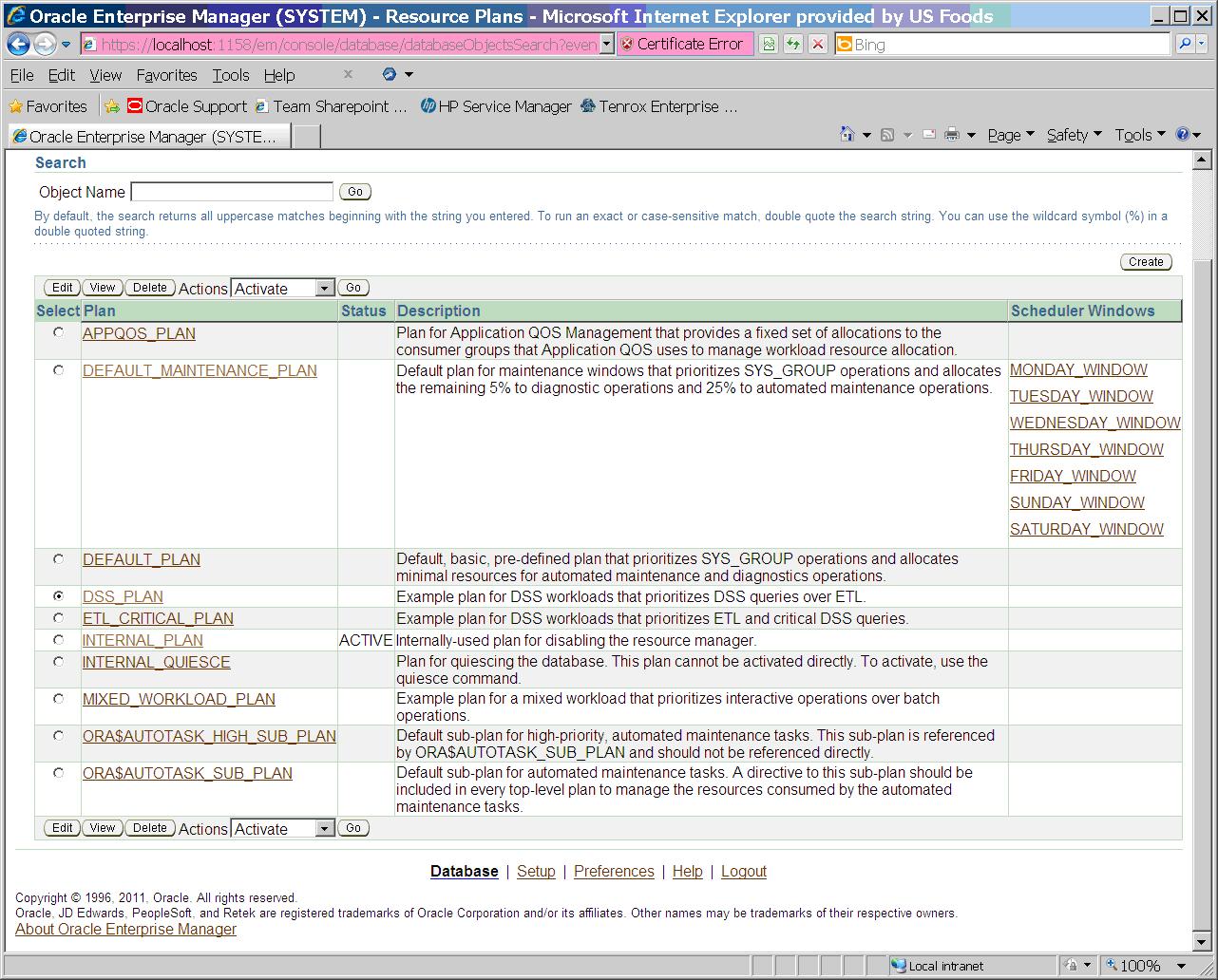
Change resource manager plan DSS_PLAN to limit DSS_GROUP consumer group to one active session.
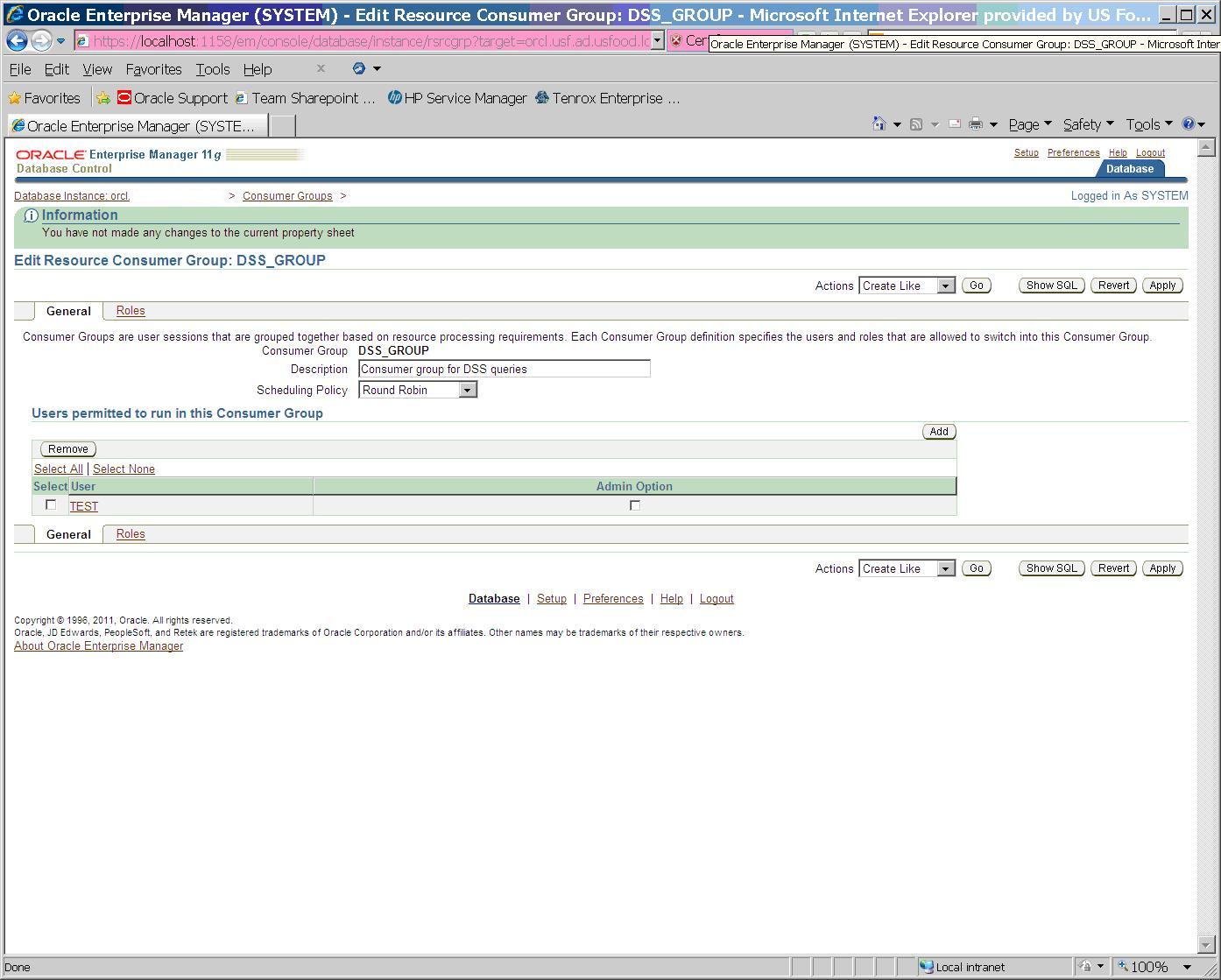
Assign user TEST to DSS_GROUP consumer group so it will be limited to one active session for our test.
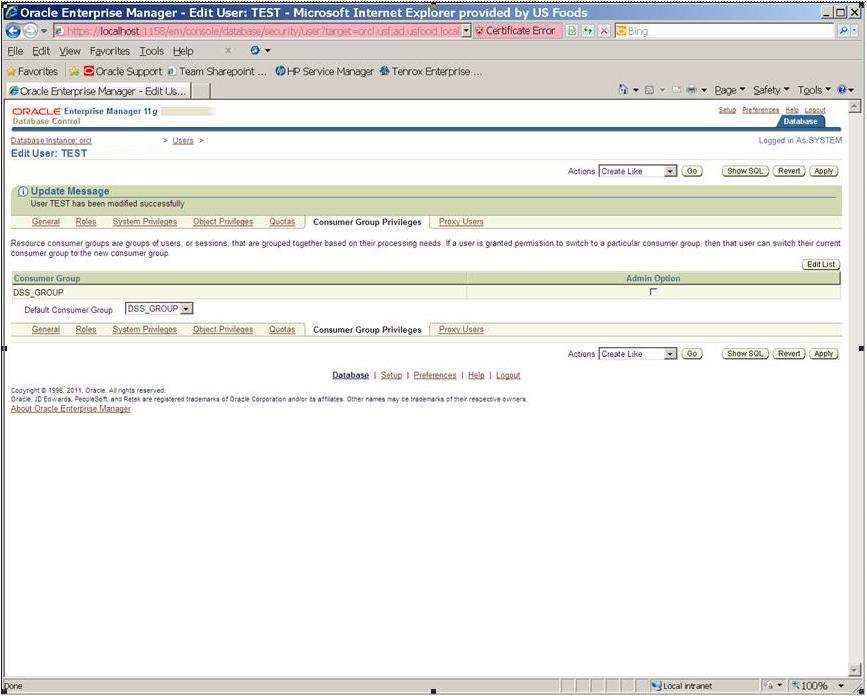
Make DSS_GROUP the default consumer group for the user TEST so it will be governed by this group when DSS_PLAN is active.
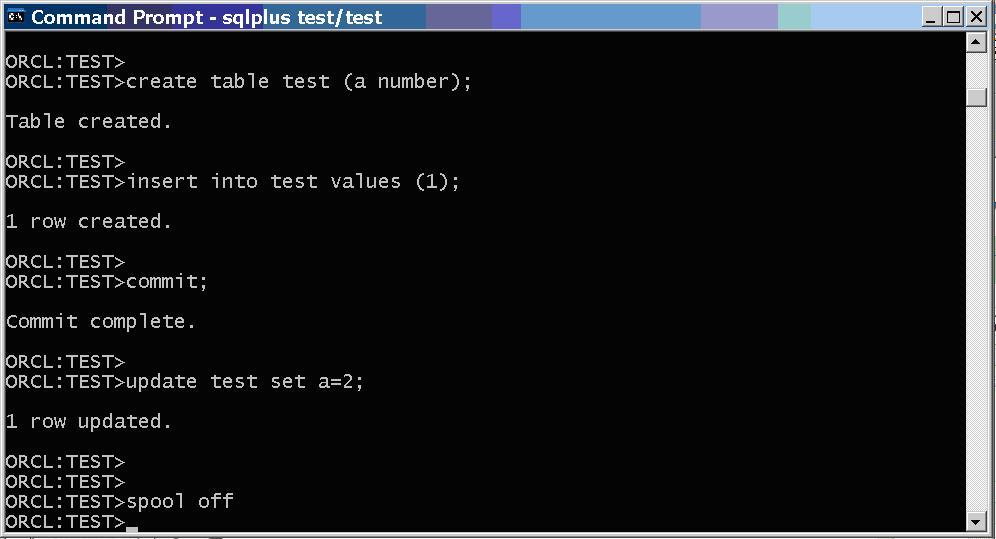
First session locks a row so second session will hang on it and be active.
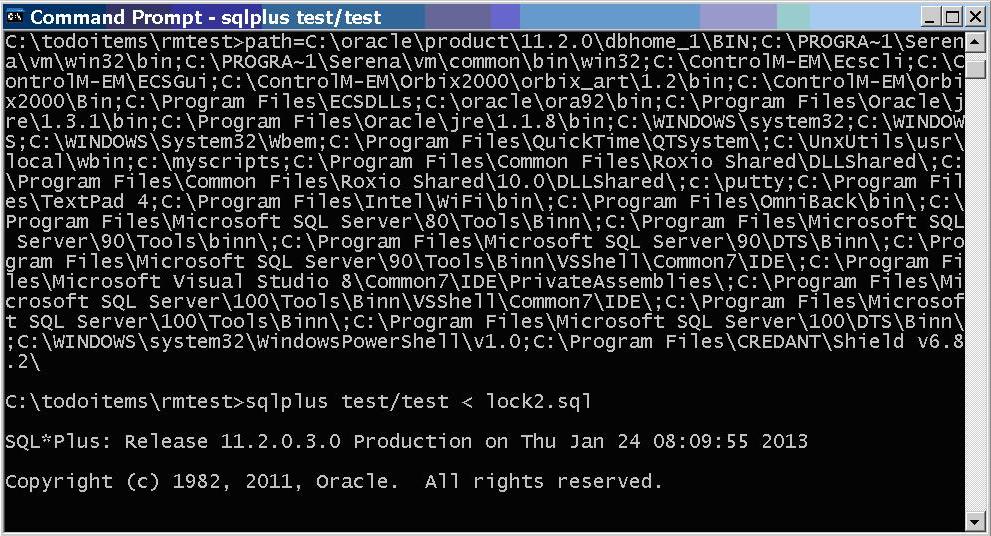
Second session doesn’t even get to the point of hanging on the lock. Hangs on the active session limit.
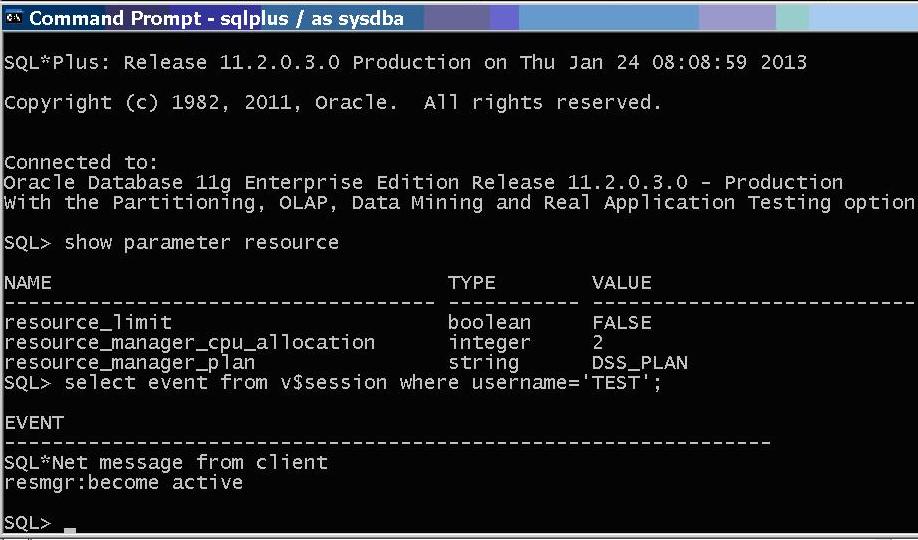
Wait is resource manager wait – not a row lock wait.
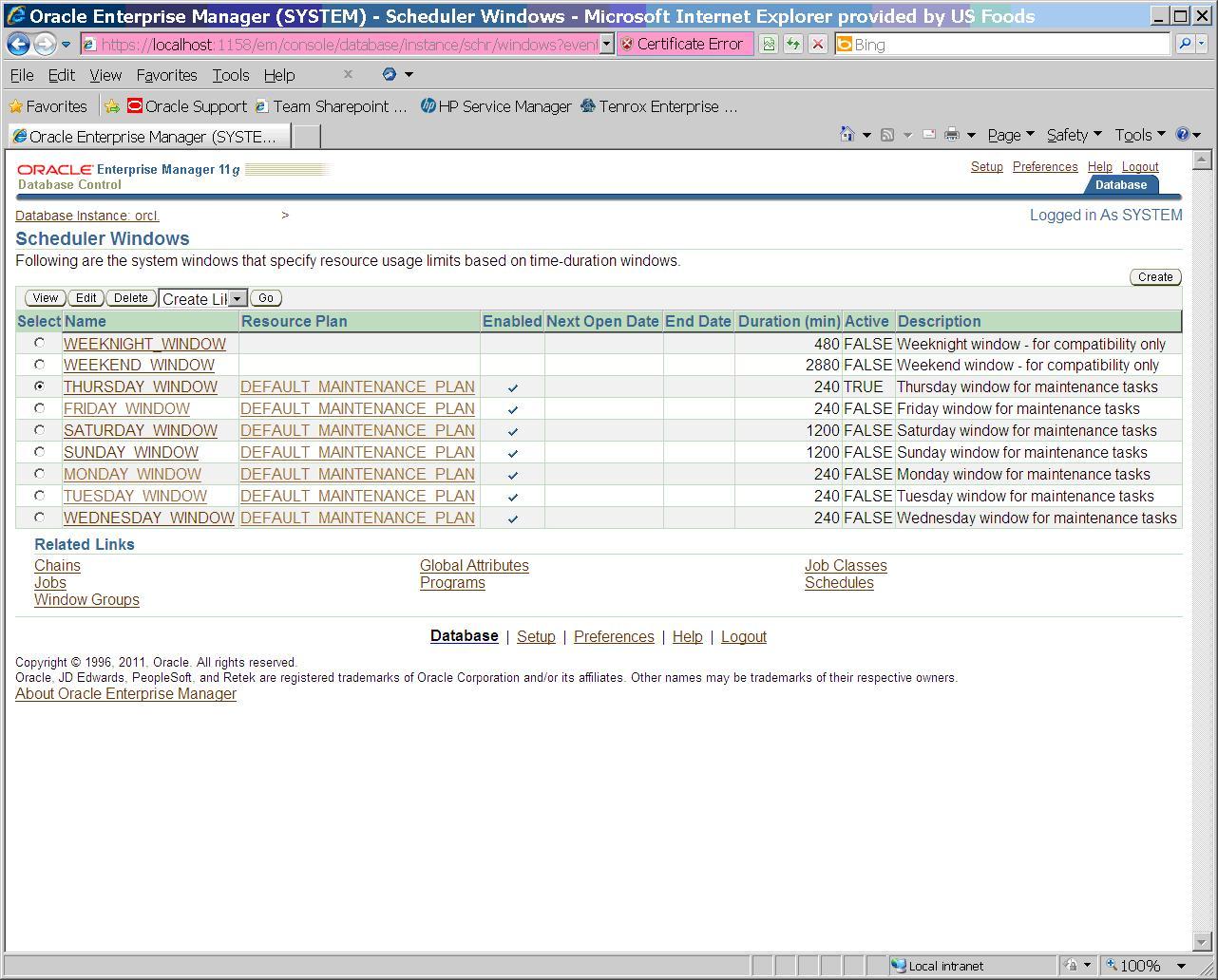
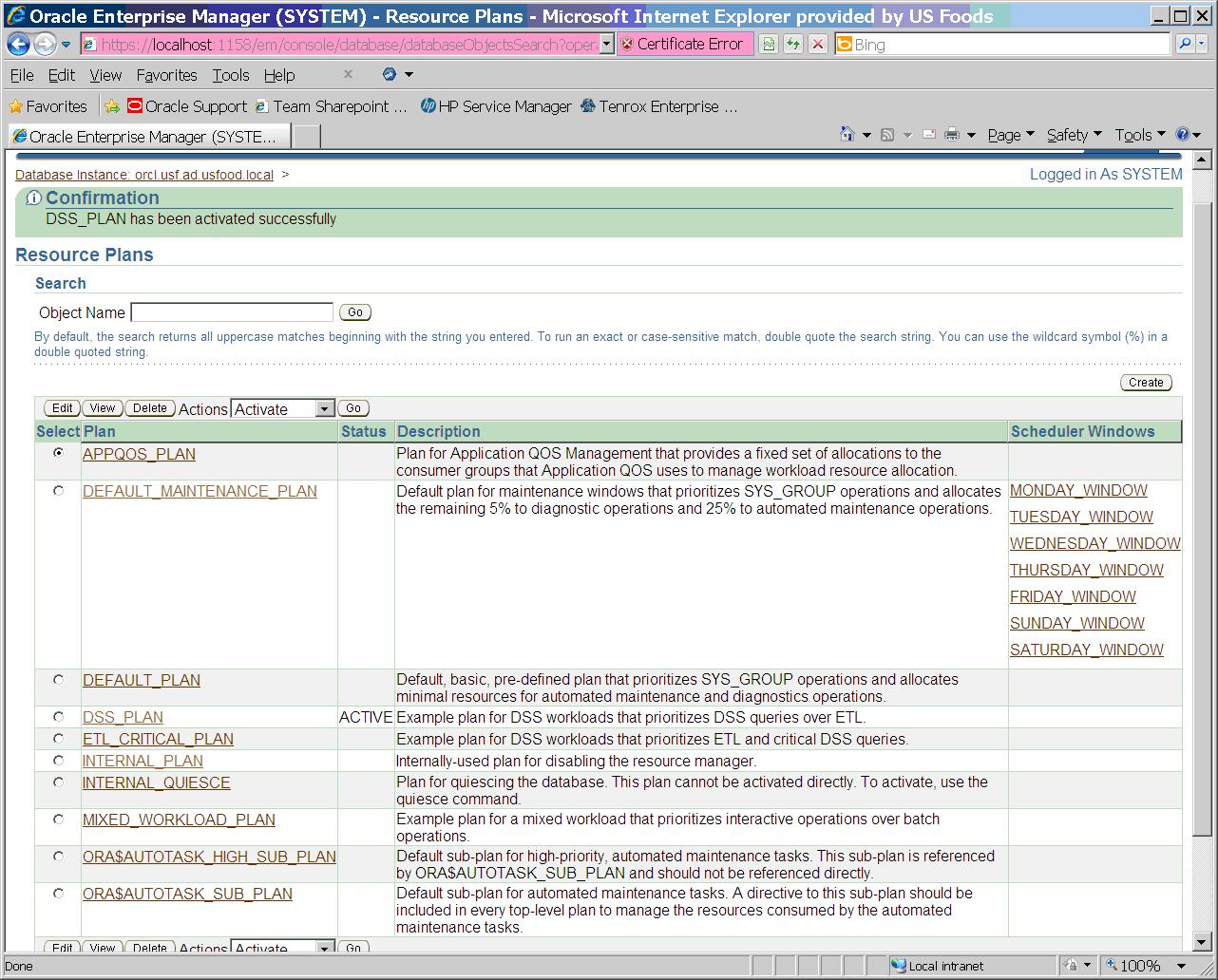
Activate today’s scheduler window.
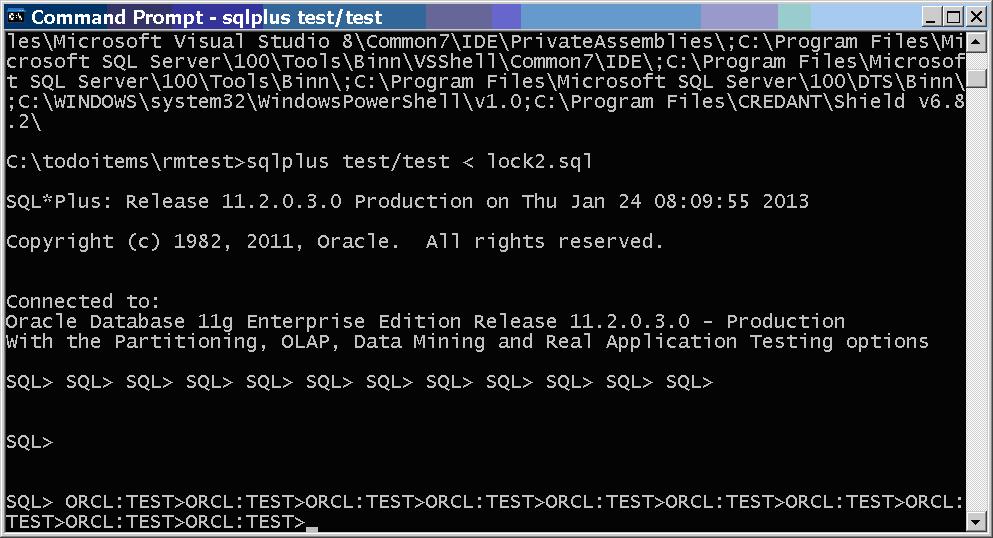
After activating window the hung session proceeds to the update and hangs on a lock wait.
Lock wait.
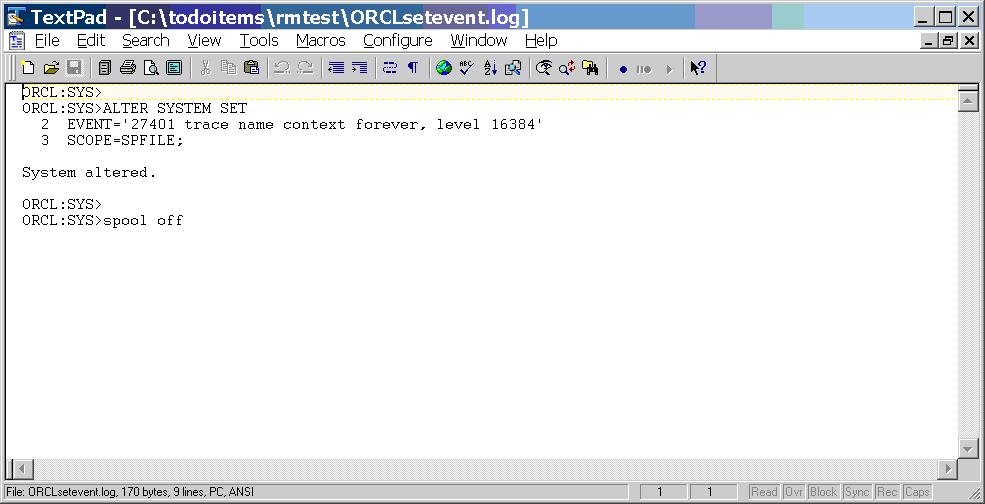
Set event and level.
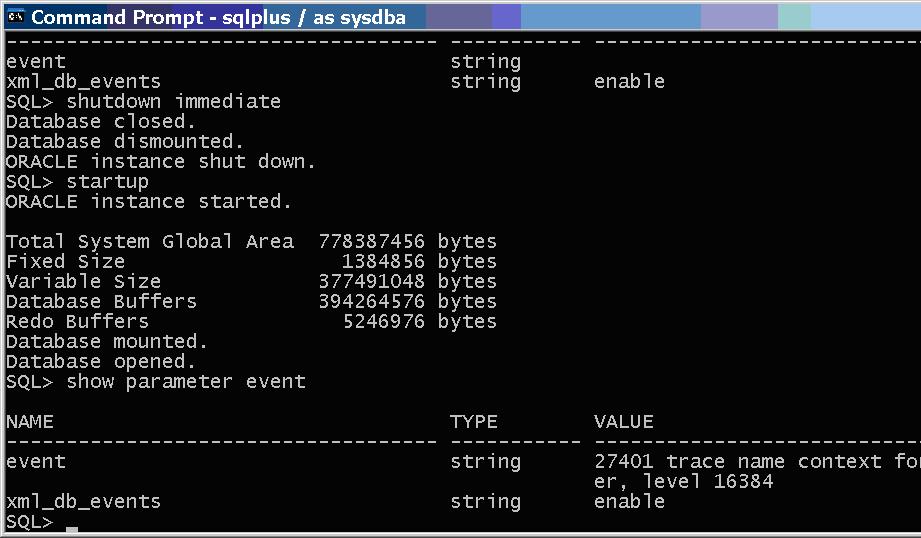
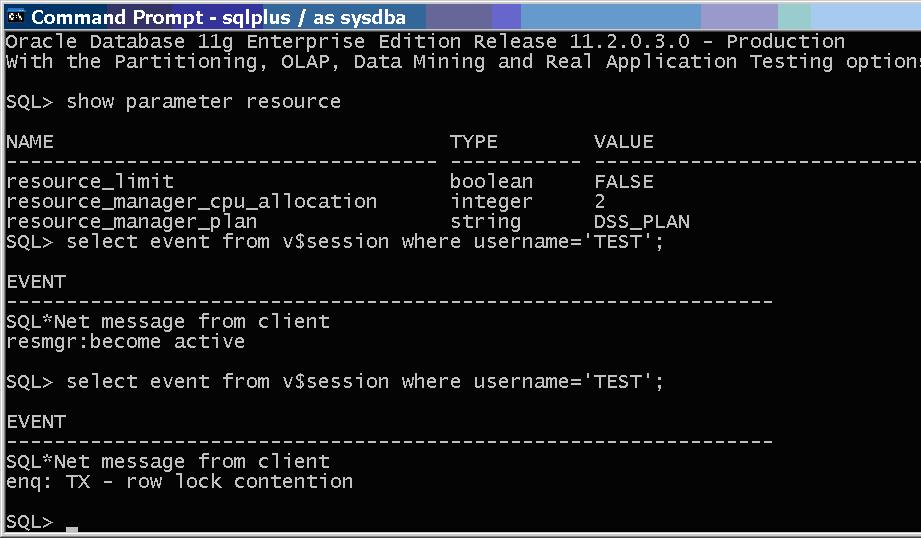
Had to bounce to get the event set. Went through the entire process again and when the scheduler window opens the resource manager wait remains and the plan parameter is unchanged.
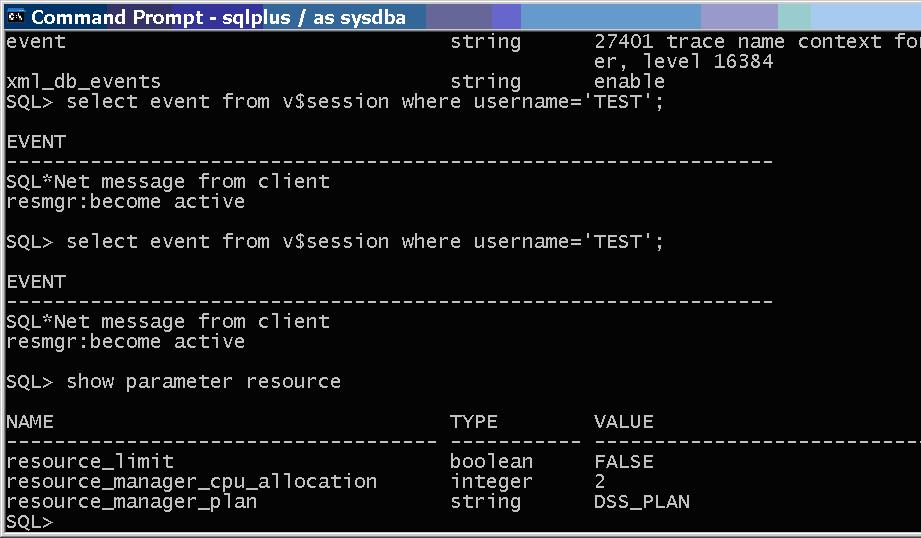
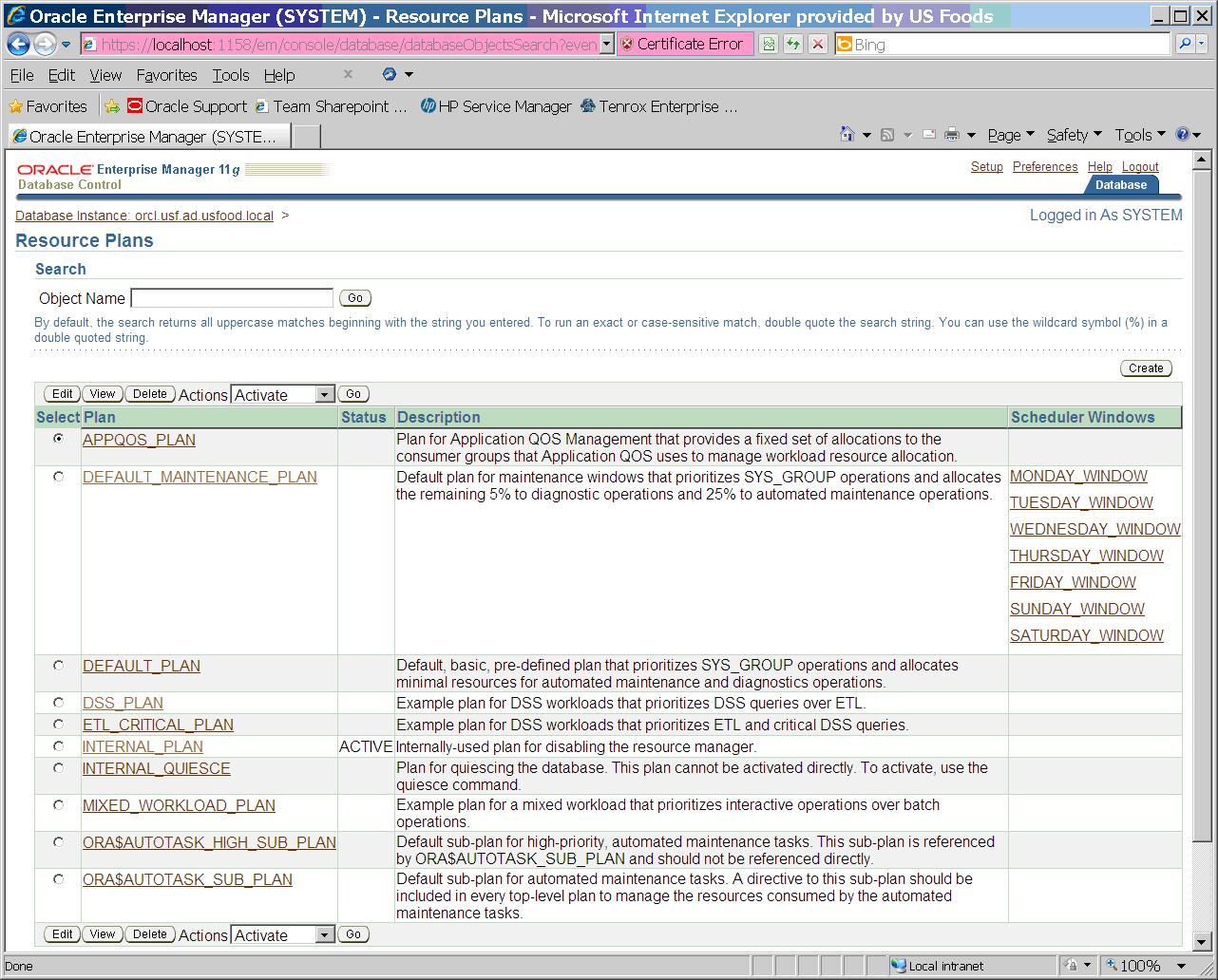
With active scheduler window and event and trace level set the plan doesn’t change.
I’m not sure how helpful this will be to people but I wanted to document this on the internet in case someone else has to deal with this event and trace level. Here are my simple locking scripts for session 1 and session 2:
-- lock1.sql -- session 1 creates table and updates a row grabbing a row lock drop table test; create table test (a number); insert into test values (1); commit; update test set a=2; -- lock2.sql -- session 2 tries to hang on a row lock: update test set a=2;
Lastly, please do not set this event and trace level on your system. I do not know all that this event does and I suspect it is causing problems on our system. All I know for sure is that it prevents the resource manager plan from changing when a scheduler window opens. Who knows what other horrible consequences there may be from setting this undocumented event? If you want to prevent the active plan from changing all you have to do is associate the plan you normally run with the scheduler window and it won’t change. So, in my example if I associated DSS_PLAN with the scheduler window then when I opened the window the plan wouldn’t change. This is much better than setting an undocumented event and trace level.
– Bobby