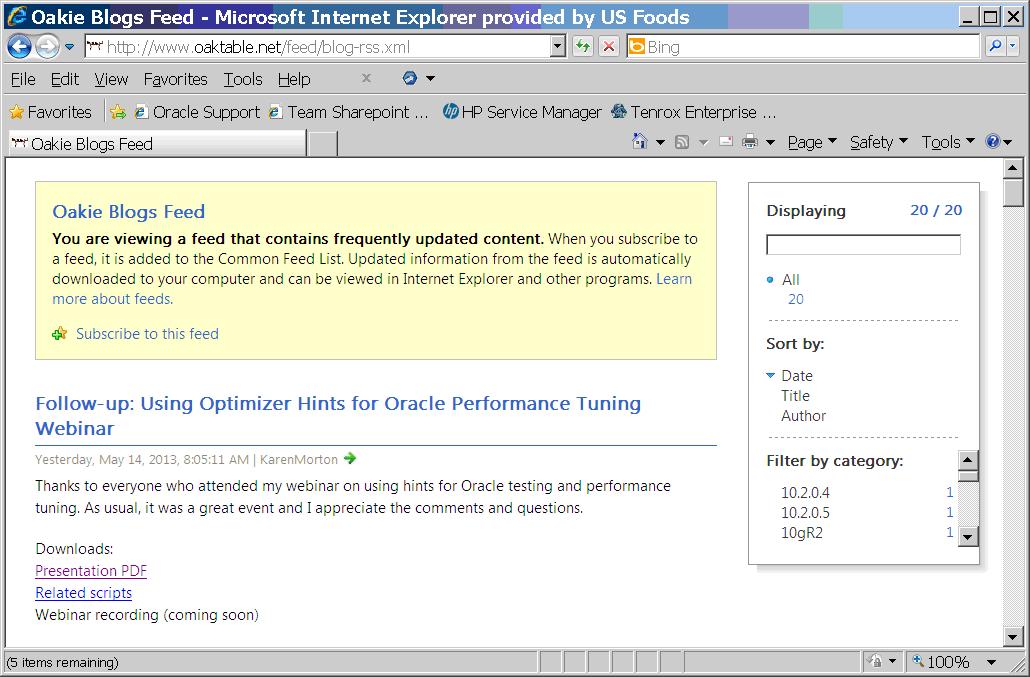
In Oracle when you compare a character and a number in a SQL WHERE clause Oracle converts the character value to a number rather than the other way around. I built a simple example to help me understand how this works. I wanted to see if the results were different depending on whether you converted the number to a character or the other way around, and found out that the results are different.
Here is how I setup the two tables I would join:
create table ntest (ncolumn number);
create table ctest (ccolumn varchar2(2000));
insert into ntest values (1);
insert into ctest values ('1');
insert into ctest values ('x');
commit;
Here is the query with the comparison of the numeric column ntest.ncolumn to the character column ctest.ccolumn and the results:
SQL> select ncolumn,ccolumn 2 from ntest,ctest 3 where 4 ntest.ncolumn=ctest.ccolumn; ERROR: ORA-01722: invalid number
This is the equivalent of adding the to_number conversion function explicitly:
SQL> select ncolumn,ccolumn 2 from ntest,ctest 3 where 4 ntest.ncolumn=to_number(ctest.ccolumn); ERROR: ORA-01722: invalid number
In both cases you get the error because it tries to convert the value ‘x’ to a number.
But, if you explicitly convert the number column to a character you don’t get the error:
SQL> select ncolumn,ccolumn 2 from ntest,ctest 3 where 4 to_char(ntest.ncolumn)=ctest.ccolumn; NCOLUMN CCOLUMN ---------- ------------ 1 1
The two choices of which column to convert produce two different results. When you design your application if you have to compare character and number values you should put in the to_char or to_number to force the conversion to be the way you need it to be, or at least you should be aware that Oracle converts a character to a number by default.
– Bobby