On December 2nd we ran into a problem with one of my scripts that uses the DBA_HIST_SQLSTAT view. It did not show the full run time of a SQL statement that ran for several hours. So, it hid the fact that the plan that the SQL statement was using was much less efficient than another better plan. This post will document the two DBA_HIST_SQLSTAT scripts that I have been using so far and will introduce a new script that should make it clearer that a SQL statement is running for several hours on a plan.
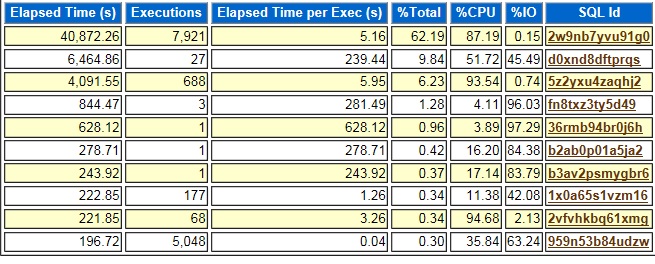
There are two scripts that are based on DBA_HIST_SQLSTAT that I use most often for tuning: sqlstat.sql, sqlstat2.sql. I use these scripts all the time to look at the performance of queries and the different execution plans that they use. But in this case the output of sqlstat.sql was misleading. Here is part of its output for the problem SQL statement am47wcwn336yj:
PLAN_HASH_VALUE END_INTERVAL_TIME EXECUTIONS_DELTA Elapsed Average ms
--------------- ------------------------- ---------------- ------------------
3771021445 04-NOV-18 05.00.15.814 AM 1 2250696
2117190322 11-NOV-18 03.01.00.265 AM 6 223502.352
1484468961 18-NOV-18 06.00.22.364 AM 1 2695964.96
2117190322 25-NOV-18 02.00.34.302 AM 3 198192.968
1139203276 02-DEC-18 07.00.21.784 AM 1 322110.53
We got a performance ticket at about 9 am on December 2nd about a session with SQL ID am47wcwn336yj running for longer than normal. Based on the sqlstat.sql output above you would think that the current plan is 1139203276 and that it is a little slower than the other plans but not terrible. The problem is that sqlstat.sql only shows you SQL executions that have completed during the hour prior to the END_INTERVAL_TIME. So, one execution of am47wcwn336yj completed between 6 and 7 am on December 2nd, but the output makes it look like it only ran for 322110.53 milliseconds which is about 5 minutes. Really it probably ran for several hours and completed around 6:05 am. So, we thought that 1139203276 was an ok plan when really 2117190322 is the much more efficient plan. But, the sqlstat.sql output confused us because it did not show the hours where am47wcwn336yj was running with plan 1139203276 but had not completed. It is easy to see why sqlstat.sql leaves out these hours if you look at this condition in its where clause:
and executions_delta > 0
This part of the where clause conditions prevents you from seeing where the SQL statement is still running. But the select clause contains a division by executions_delta so you cannot have divide by zero so that is why I excluded it.
When I am working on a long running SQL statement that spans two or more hours, I run sqlstat2.sql after I run sqlstat.sql. Sqlstat2.sql shows all the time spent per hour regardless of whether a SQL statement’s execution completed. It does not have the condition requiring executions_delta to be > 0 because it does not divide by that column. Here is the output for am47wcwn336yj:
PLAN_HASH_VALUE END_INTERVAL_TIME EXECUTIONS_DELTA ELAPSED_TIME_DELTA
--------------- ------------------------- ---------------- ------------------
3771021445 04-NOV-18 03.00.43.465 AM 0 3584030311
3771021445 04-NOV-18 04.00.27.516 AM 0 3588264762
3771021445 04-NOV-18 05.00.15.814 AM 1 2250695998
2117190322 11-NOV-18 03.01.00.265 AM 6 1341014109
1484468961 18-NOV-18 02.00.07.772 AM 0 3171408998
1484468961 18-NOV-18 03.00.58.545 AM 0 3648125526
1484468961 18-NOV-18 04.00.44.680 AM 0 3586687594
1484468961 18-NOV-18 05.00.32.832 AM 0 3592026797
1484468961 18-NOV-18 06.00.22.364 AM 1 2695964960
2117190322 25-NOV-18 02.00.34.302 AM 3 594578904
1139203276 02-DEC-18 02.00.14.082 AM 0 480039949
1139203276 02-DEC-18 03.00.05.255 AM 0 3591464884
1139203276 02-DEC-18 04.00.50.936 AM 0 3645014119
1139203276 02-DEC-18 05.00.40.304 AM 0 3591817904
1139203276 02-DEC-18 06.00.31.820 AM 0 3587861998
1139203276 02-DEC-18 07.00.21.784 AM 1 322110530
1139203276 02-DEC-18 09.00.58.127 AM 0 2028205794
1139203276 02-DEC-18 10.00.37.793 AM 0 3582326580
Here you can see that plan 1139203276 ran between 1 and 7 am on 02-DEC-18 and completed and then ran between 8 and 10 am and never completed. We ended up killing the long running session and we reran the SQL another way so there is no more history of it. The problem with sqlstat2.sql is that it does not show average elapsed time per execution like sqlstat.sql does. It just shows the total elapsed time for all executions, if any. This is because we don’t divide by executions_delta. Also, the units are microseconds instead of milliseconds. I find milliseconds to be easier to use.
To me looking at the output from sqlstat.sql and the output from sqlstat2.sql 2117190322 is the best plan. It is clear to me because I wrote these two scripts and am used to the way they look in this situation. If you go back to the first output, you can see that plan 2117190322 averages less than 224 seconds per execution (223502.352 ms and 198192.968 ms). Plans 3771021445, 1484468961, and 1139203276 ran for multiple hours. You can tell this because there are multiple consecutive hours with those plans and 0 executions.
I have used sqlstat.sql and sqlstat2.sql a lot as they are but today, I got the idea of combining them into a script that shows average elapsed time per execution for a given hour and includes hours where an execution did not complete. I have not used it yet in a real performance tuning situation but here it is, cleverly named sqlstat3.sql. Here is its output for this situation:
PLAN_HASH_VALUE END_INTERVAL_TIME EXECUTIONS_DELTA Elapsed Average ms
--------------- ------------------------- ---------------- ------------------
3771021445 04-NOV-18 03.00.43.465 AM 0 3584030.31
3771021445 04-NOV-18 04.00.27.516 AM 0 3588264.76
3771021445 04-NOV-18 05.00.15.814 AM 1 2250696
2117190322 11-NOV-18 03.01.00.265 AM 6 223502.352
1484468961 18-NOV-18 02.00.07.772 AM 0 3171409
1484468961 18-NOV-18 03.00.58.545 AM 0 3648125.53
1484468961 18-NOV-18 04.00.44.680 AM 0 3586687.59
1484468961 18-NOV-18 05.00.32.832 AM 0 3592026.8
1484468961 18-NOV-18 06.00.22.364 AM 1 2695964.96
2117190322 25-NOV-18 02.00.34.302 AM 3 198192.968
1139203276 02-DEC-18 02.00.14.082 AM 0 480039.949
1139203276 02-DEC-18 03.00.05.255 AM 0 3591464.88
1139203276 02-DEC-18 04.00.50.936 AM 0 3645014.12
1139203276 02-DEC-18 05.00.40.304 AM 0 3591817.9
1139203276 02-DEC-18 06.00.31.820 AM 0 3587862
1139203276 02-DEC-18 07.00.21.784 AM 1 322110.53
1139203276 02-DEC-18 09.00.58.127 AM 0 2028205.79
1139203276 02-DEC-18 10.00.37.793 AM 0 3582326.58
The nice thing is that you can see that 2117190322 ran 6 times averaging 223502.352 milliseconds on November 11 and 3 times averaging 198192.968 milliseconds on November 25th. Plus, you can see that the other plans span multiple hours. Note that the plans that span a full hour run for about 3600000 milliseconds which is an hour so that supports the idea that the SQL statement is active throughout the entire hour. I have only shown some of the total output to fit on the screen, but the full output includes more information such as a CPU and IO breakdown of the run time.
Anyway, the point is that the main DBA_HIST_SQLSTAT query that I use, sqlstat.sql does not show SQL statements that run for several hours very clearly. You can figure it out using sqlstat2.sql in addition to sqlstat.sql. The new sqlstat3.sql script may make it easier to diagnose multi-hour SQL statement executions in the future without having to use two scripts.
Bobby
P.S. See this post about how I consolidated sqlstat.sql, sqlstat2.sql and sqlstat3.sql into one script, sqlstat.sql:
https://www.bobbydurrettdba.com/2020/04/14/fixed-issue-with-dba_hist_sqlstat-script/